SPITBOL Programming by/for Classicists: Accessing and Analyzing Classical Texts
by
Prof. Dr. Burkhard Meissner
until 2004:
Martin-Luther-Universitaet Halle-Wittenberg
Institut fuer Klassische Altertumswissenschaften
since 2004:
Helmut-Schmidt-Universität/Universität der Bundeswehr Hamburg
Holstenhofweg 85
D-22043 Hamburg
Tel.: (49)-40-6541-3396
Fax.: (49)-40-6541-2298
[email protected]
Abstract: This article describes a system to interact with and to interrogate beta code text data bases of ancient literary material on 32-bit Intel(R) machines. This system has been designed to interface as flexibly as possible not only with different input text material, but also with other programs and output formats to be used in complex statistical studies of ancient texts.
Introduction: Purpose and History of the V&F system
Classicists‘ data are largely textual data. Over the last twenty years, much work has been invested in putting classical texts on record. The Oxford Text Archive has been collecting and disseminating classical texts in different machine- readable formats since long. Thesaurus Linguae Graecae and Packard Humanities Institute provide comprehensive collections of Greek classical texts, Latin literature and epigraphical as well as papyrological documents on CD-ROMs. The latter texts have been encoded using David Packard’s „beta code“. This code has become a quasi-standard for the encoding of uncommon symbols and Greek script, and the SGML standards of the Text Encoding Initiative have adopted beta code to encode classical Greek. In beta code, something like Arist., Eth. Nic. 1106b36-1107a2
would be represented as
$@*)/ESTIN A)/RA H( A)RETH E(/CIS PROAIRETIKH/, E)N
MESO/THTI OU)=SA @1 TH=| PROS H(MA=S, W(RISME/NH| LO/GW|
KAI W(=| A)N O( FRO/NIMOS O(RI/SEIEN.
In addition to encoding Greek with a 7-bit code, the above text collections use a special block-structure with 8 KB blocks to address the texts. Bytes above 127 function as record-separators and encode the references for the following record. Works and 8-KB text blocks are referred to with their encoded references by a second file known as „index“ (.IDT) file. This structure allows rapid access to single items within a larger text space. The file and record structure has been adopted, at least as an option, by other text distributors, among whom J.Malitz‘ Eichstaett inscriptions (IGEyst) figure prominently. Rather recently, commercial distributions with proprietary file structures offer access to special classes of texts, like the patristic collections of Brepols‘ or Chadwyck & Healey’s version of Migne’s Patrologia Latina (All these text resources are accessible at Halle on a local NetWare(R) 3.12 server. The kind of classics computing that is being done at Halle is succinctly described in M.Nenninger 1994).
Unlike such proprietary systems, which come bundled with access software, beta code texts are distributed without software that would be operating system- dependent. There are, however, several software packages to access these texts on different platforms, but originally they had been designed for a specially- designed classics computing platform, the Ibycus computer, a 68000-family machine with specialized Greek character display and CD-ROM drive. Economical and technical developments turned against dedicated domain-specific hardware devices in the early nineties. Its graphics versatility brought early prominence to the the Apple Macintosh(R) among classicists in those days, and accordingly there are several systems to utilize beta code texts on the Mac, notably Anna Santoni’s SNS-Greek & Latin (For a brief description of this system see: A.Russo 1992; A.Santoni 1990; A.Santoni & L.Bondi & A.Russo 1992.), which is succinctly described in an online article in the CRIBeCu newsletter, which the Scuola Normale Superiore di Pisa, Italy publishes regularly in printed form as well as eletronically. Limited performance limited acceptance of IBM(R)-compatibles for tasks that required non-Latin script and a large address space, but the emergence of 32-bit Intel processors in the late eighties/early nineties reversed the situation: IBM(R)/Compaq(R)-compatible computers became an economical investment, and Mark Emmer (Catspaw, Inc., Salida Co.) provided an excellent SPITBOL-386 compiler implementation of the SNOBOL4 language for those processors, which allowed for the linking of externally assembled machine routines. Without these, displaying of non-Latin scripts and efficiently decoding the text‘ block-structure would hardly have been possible. On the other hand, the SNOBOL4/SPITBOL pattern language, despite all that might been argued against the allegedly archaic control structure design of the language, is especially suitable to flexibly accessing textual data. Furthermore, SNOBOL4/SPITBOL’s CODE() function provides transparent access to all of the system’s functions; wrapped by appropriate error-checking routines, the CODE() function gives the user a flexible tool for creative non-numeric programming unrivalled by other programming languages.
Before actually writing a software system as complex as this, some fundamental design decisions had been taken:
Despite its character as a quasi-standard, beta code allows for variations and extensions, notably for documentary texts, where meta-textual information is included. Existing software performed poorly with documents and fragmentary texts, which are all-too frequent within ancient literature. V&F tries to be as flexible as far as character coding is concerned, and it attempts at reproducing all levels of information that are present in the texts.
As a matter of fact, there are inconsistencies and errors in some of the text files. If possible, V&F corrects such errors (e.d.: spurious inline hyphenations) or marks them (e.d.: erroneous references). Internal data structures reflect the structure of the text files, but are sufficiently independent from these not to interfere with proper functioning of the program’s routines.
The V&F system allows for free access to and movement within the texts. Its export facilities are user-configurable and flexibly interface to a wide variety of printers, word processor and file formats.
The system uses an extended version of the SPITBOL pattern language to specify string targets and search patterns, without giving the user access to the entire runtime compilation system, though.
The system contains its own indexing and concordance production machine to allow for the exploitation of the statistical potential of electronic texts.
Development of the system began in 1990, beginning with Hercules(R) graphics and gradually including other graphics standards as well (CGA, EGA, VGA). By now, the system consists of the main access program to beta code text data bases (V&F/Additional reading on V&F: B.Meissner 1991; U.Kindermann 1992; C.Schaefer 1993; B.Meissner 1993.) and a variety of interface utilities to convert or print V&F output and to convert third-party texts to beta code for access. Overall, we have written about 400 source modules with more than 50000 lines of code (ca. 400 pages of printed A4 output). Ca. 70% of the code is SPITBOL, 30% assembly language. The system runs with two different DOS extenders under PC/MS-DOS(R), MS-Windows(R) 3.n, DESQView/X(R) and OS/2(R).
-
- M1
-
- M2
-
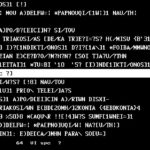
- M3
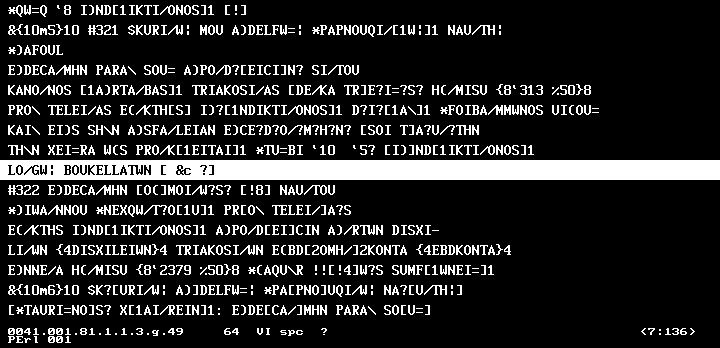
-
- M4
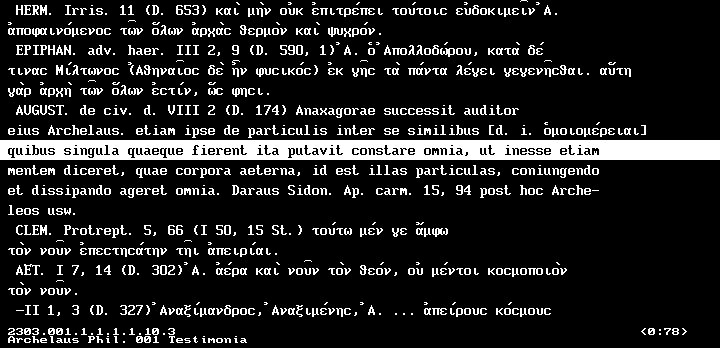
-
- M5
-
- M6
Concepts and Program Structure
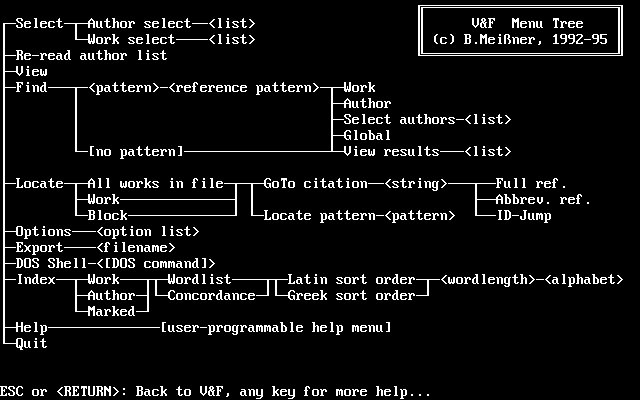
The startup-defaults of V&F, the main module of the entire system, are controlled by a text profile which defines default author lists to be read on startup, default display settings etc. Once the author table has been read, the user may make selections of authors and single works. The author/work structure has only metaphorical meaning for sets of documents like inscriptions or papyri, but generally, this author/work metaphor has been adopted coherently by all beta code text bases, and V&F remains faithful to this. The overall structure of the V&F menue system as it ist presented to the user is rather simple:
The above map (M1) shows menue levels from left to right (M1): Options on the leftmost bar make first-level selections, to the right follows what is one level below etc. A status line gives information about the author and work selected (if any), about the reference of the present line and about hierarchical reference-level meanings.
Normally, the user starts by manually selecting an author from a searchable pick-list and one of the corresponding works from a similar list. The text screen would then look like this:
MAIN MENU:
Select
Re-read author list
View
Find
Locate
Options
Export
DOS Shell
Index
Help
Quit
[Author].Work…Book.chapter.section.line
0003.001.1.1.t.1.1.1
Thucydides Hist. 001 Historiae
Practically, after selecting an author and text, viewing it would be the next step. Viewing is done in graphics mode to enable non-Latin scripts. The system can display much more than the usual 256 or 512
Picture M2 above!
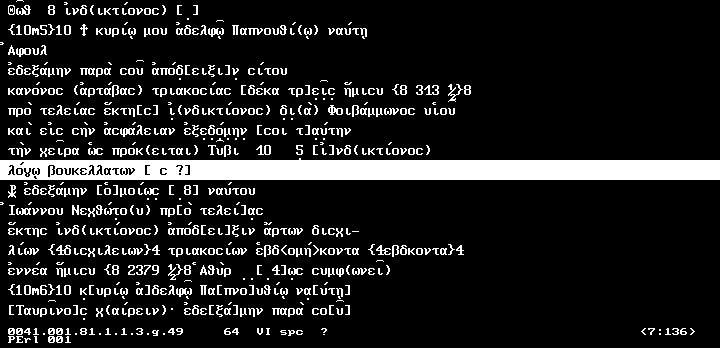
characters or combinations of characters. The text strings are stored in memory in large arrays which correspond to 8KB blocks of the texts. These SPITBOL arrays contain two dimensions, the text lines themselves which ares stored as beta code strings without any conversion taking place, and the decoded reference levels, also stored as strings, with optionally added markers if the references are found to be incorrect by the program. Thus, the general structure of the text files is preserved, smoothly interfacing, however, with SPITBOL’s strengths at data structures. On the down side, this requires much conversion to be done while actually displaying the texts. This job is left to one of the larger assembly routines which takes a string to be displayed, gets optional parameters (starting font etc.) and while decoding the beta codes writes them directly to the actual graphics screen. This display function is very powerful in that it handles uncommon symbols, if so required; it may, however, be directed by the user to display the text in
Picture M3 above!
unconverted mode to see directly the beta codes themselves. We did not want to hide any information from the user that might be present in the files and which might me mis-represented by any piece of software.
Picture M4 above!
There are several possibilities to directly jump to a given portion of the text. This is done via the Locate command. Either, the user specifies a given reference or a SPITBOL pattern which will then be applied to the following text lines (up to the end) to directly load the specified portion. With a given reference, jumping backward is possible, too. Conceptually, distinguishing the locate operation from finding, and consequently the introduction of two menue entries derives from academic reading practices: Opening up a book and reading from a specified page or paragraph is a practice entirely different from looking up an index or table of contents and consulting the text like a reference manual. Both activities, however, are common classicists‘ practice, and V&F tries to reflect these different attitudes towards texts. The Findcommand, then, applies a look-up pattern to a single work, all the works of an author or all works of all authors present in the author list – this group of authors can be restricted using filters, manually modified or altogether left untouched. Whereas after locating a specified portion of text the user is presented with either the graphics view of that portion – if it could been found – or otherwise with the main menu, finding results in a list file to be written which can then be viewed like an index of matching lines. Since looking up such an index is a common activity, there is a shortcut from the Find menue to viewing this find result list – if any. Its entries read like this:
Marcus Tullius Cicero=Cicero
055 De Officiis
0474.055.1.1.1.3.52.5
DEBEAS UT UTILITAS TUA COMMUNIS SIT UTILITAS
Entry #: 57
Entries in list: 69
Deleted: 0
The list itself can be searched for substrings or collocations, entries can be deleted, but its main function is to provide rapid access to the context itself, which may be selected by just pressing the RETURN key and viewed from the menue with the View command. The program contains a macro recorder to unify such sequences of operations and to assign them to single keystrokes.
Since the texts themselves are held in memory in a form losely resembling the file format, which contains hyphenations, special codes etc., Locate and Find operations cannot be performed directly in memory. Rather, the program runs special conversion routines that read, convert and search entire 8 KB blocks at once, resolving hyphenations, removing special codes, converting to standard capitalization etc. These conversions are used, too, to produce indices and concordances of texts, with an index being defined as a word list, which shows numbers and references of occurrences and a concordance as an index which shows text lines, too. A concordance can be used, too, to get a first impression of word usage in author, a single work or any marked portion of a text:
Concordance of Sevius Nicanor (LAT0642)
# 1 AC: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 2 DOCEBIT: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 3 HUIUS: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 4 IDEM: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 5 LIBERTUS: 1
1.1.1.1.1.1.1 Suet. Gram. et Rhet. 5.1
Sevius Nicanor Marci libertus negabit.
# 6 MARCI: 1
1.1.1.1.1.1.1 Suet. Gram. et Rhet. 5.1
Sevius Nicanor Marci libertus negabit.
# 7 MARCUS: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 8 NEGABIT: 1
1.1.1.1.1.1.1 Suet. Gram. et Rhet. 5.1
Sevius Nicanor Marci libertus negabit.
# 9 NICANOR: 1
1.1.1.1.1.1.1 Suet. Gram. et Rhet. 5.1
Sevius Nicanor Marci libertus negabit.
# 10 POST: 1
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
# 11 SEUIUS: 2
1.1.1.1.1.1.1 Suet. Gram. et Rhet. 5.1
Sevius Nicanor Marci libertus negabit.
1.1.1.1.1.1.2 Suet. Gram. et Rhet. 5.1
Sevius post huius idem ac Marcus docebit.
STATISTICAL EVALUATION
Frequency classes:
1:
1,2,3,4,5,6,7,8,9,10
2:
11
Frequency distribution:
Words total: 12
Words picked: 12
Percent. words picked: 100.000
Different words: 11
Different/picked words: 0.916
FREQU. NUMBER WORDS IN VOCAB WORD PERC. SEL. PERC. OF PERC. WORDS
SUCH FREQUENCY TOTAL TOTAL VOCAB. WORDS IN FREQ.
1 10 10 10 10 90.909 83.333 83.333
2 1 2 11 12 100.000 100.000 16.666
This small example gives a rough impression of what can be deduced from a concordance: It shows all the words in alphabetical order (optionally in Greek or Latin) and gives a rough overview of word usage. It profiles word frequencies, without applying lemmatizing algorithms. So it rather than displaying a given text’s lexicon allows merely allows for an overview of it.
All V&F’s operations result in certain default files to be written, most of them being obsolete afterwards. Marked and exported portions of texts, Find result lists and concordances, however, will be of significance to the user independently of whether V&F is actually running or not. For this, a whole set of programs interfaces V&F output to word processors, printers and external analysis programs. All these interface programs are called independently from the operating system shell (which is accessible from inside V&F, too), but for the more often to be called interface programs an integration platform is provided that allows calling these routines in a point-and-shoot manner. This is especially useful for concordances and saved texts, since besides resolving line references V&F outputs these items in unconverted beta code. The external routines which are accessible from the integration shell provide the following conversions and operations:
Printing:HP-LaserJet(R) and compatible
24-pin-printhead printers (NEC(R)/Epson(R) compatible)
HP-DeskJet(R) and compatibles (not fully supported, needs additionally installed memory)
Conversion:word processors:WordPerfect(R) 5.1 and above
NotaBene(R) IV
ChiWriter(R) 3.nn
file formats:plain ASCII (with hyphenations resolved)
Oxford Concordance Program(R)
free format conversion: user-programmable conversion routine (With this batch routine, arbitrary conversions can be realized. There are, for example, conversion tables for GreekTex by K.Dryllerakis.)
Thus, the V&F package provides basic routines to access beta code texts for historical and philological research.
V&F and Computerized Stylometry
One of the main goals of the V&F development was to provide a flexible platform on which to rest to perform computerized statistical analyses on ancient text data. Naturally, the operations vary with the enquiry to be performed and with the nature of the texts involved. Pure ASCII versions of the texts with resolved hyphenations and all special codes removed are therefore more suitable to running refined statistical tests than beta code texts, since this saves on time- consuming conversions and calculations. An external program is provided that produces bare ASCII from beta code output, resolves all special coding and applies case folding to the strings, if necessary. Its output from our initial example would look like:
ESTIN ARA H ARETH ECIS PROAIRETIKH EN MESOTHTI OUSA
TH PROS HMAS WRISMENH LOGW KAI W AN O FRONIMOS
ORISEIEN
One of the uses to which V&F was put once the system had been completed was a series of analyses of a series of later Roman emperor biographies, the so-called „e;Historia Augusta“e;. These biographies, allegedly written by six spurious authors claiming to date from Diocletian’s time onwards, have since 100 years been generally regarded as the work of only one later writer or forger (With lit.: B.Meissner 1993), who perhaps concealed his identity to hide an underlying anti-Christian attitude before a generally Christian environment. There had been attempts at proving this hypothesis with statistical tests (I.Marriott 1979) about sentence lengths distributions and parts of speech at the beginnings and ends of sentences, with sentences defined as sequences of words between punctuation marks. Proving the coherence of the text under this assumption does, however, not in itself establish its stylistical unity as much as it proves the coherence of modern editorial practice (D.Sansone 1990). Recent studies have demonstrated that sentence lengths and usage of parts of speech in Latin literature were determined more by literary genre and general conventions than personal style (B.Frischer & D.Guthrie & E.Tse & F.Tweedie 1996; for French Literature: C.Muller & E.Brunet 1988; compare S.D’Arco Avalle 1991 84f.); even in modern literature statistical fundamental characteristics of language are more influenced by literary convention than personal style. This state of the enquiry, then, required a re-examination of the argument with new methods. It was assumed that function word frequency is analytically superior to aspects that are sentence lenghts-dependent (F.Mosteller & D.L.Wallace 1964; A.J.P.Kenny 1977; A.J.P.Kenny 1978; A.J.P.Kenny 1979; F.Damerau 1975), since they vary less with modern editing, because of their relative invariance to (changing) contents and because of the indeclinability of these words.
„Cluster“ Analysis: An Analytical Tool
For what followed, getting „bare“ texts from beta code output via the ASCII conversion routine was essential. To test the underlying assumption of function word frequencies and variances varying with authorship, the texts of different Latin authors were simply compared with respect to words like et, in, ut and non. They turned out to use these words with frequencies different enough to corroborate the assumption that with small function words we have an indicator of stylistic differences that allows for the identification not only of differences of genre, but of personal style, too (B.Meissner 1992; B.Meissner 1994, forthcoming).
Judgement on the linguistic unity or diversity of a text can be much improved, if the observed phenomenon can be displayed graphically in a curve. If word frequencies scattered at random over a given text, frequency differences could hardly be regarded as an indicator of significant stylistic differences; if however, marked peaks and trends can be observed, these might be indicators of a difference in style that would then have to be proved by statistical means. A program which displays the frequency of a given word or combination within a given context of words graphically would thus be of some help for determining whether or not a given text, on the whole, shows homogeneity or disunity, provided the size of the given context be chosen appropriately.
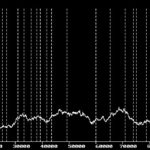
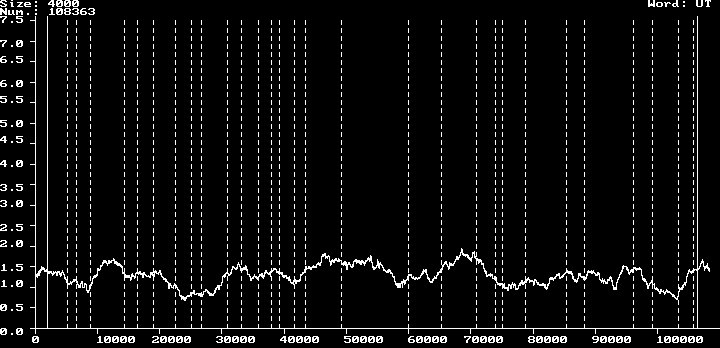
Picture M5 above!
number 108363
min. % 0.67
max % 1.95
avg. % 1.28
scatt. wid. 1.27
scatt. wid. %avg. 99.71
variance s2 0.06
var. % avg. 4.66
devi. 0.24
devi. % avg. 19.09
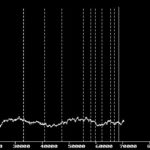
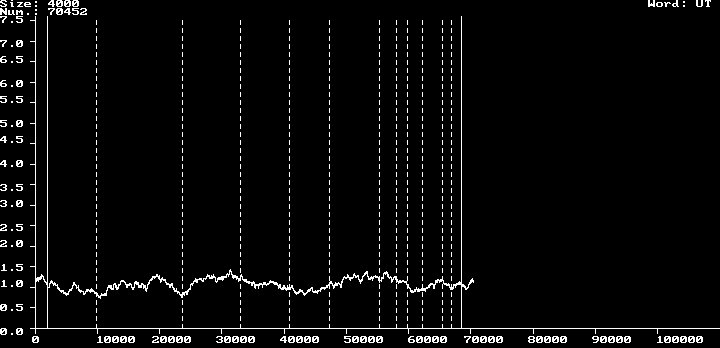
Picture M6 above!
number: 70452
min. % 0.72
max. % 1.42
avg. % 1.06
scatt. wid. 0.70
scatt. wid. %avg. 65.85
variance s2 0.02
var. % avg. 1.62
devi. 0.13
devi. % avg. 12.34
Diagrams like the ones above show the output of such a program, applied to the texts of the Historia Augusta and to the biographies of Suetonius. The diagrams show a higher variation of the frequency of ut in the Historia Augusta than in Suetonius. Technically, these results have been obtained in a two-stage process, after the text had been converted to raw ASCII. A first program applies what I call „cluster“ analysis to the texts. For each single word in the text, it writes a percentage value into a file, which gives the frequency of the word (ut) within a „cluster“ of given size (4000 in the above example; this value can be chosen at will by the user of CLUSTER). A second program collects the maximum and minimum values, calculates an appropriate scale (if not fixed by the user) and writes the graphics curves, which can then be saved to a file to be processed by other programs.
The „cluster“ technology has been implemented using SPITBOL’s list processing capability and the DATA() function. The CLUSTER() function defines an item, which contains a pointer to the top and last elements of the list, the pattern to be applied to the word to check, if it matches, the actual and required numbers of entries in the list and a running number of matching items in the list:
DATA(‚CLUSTER(TOP,LAST,PATTERN,IST_NUMBER,SOLL_NUMBER,PASSEND)‘)
Single list entries (ELEM) are defined in the usual manner:
DATA(‚ELEM(VALUE,NEXT)‘)
The list, then, is a singly-linked list with pointers to its first and last elements. It grows at the end, and once it has reached its size (IST_NUMBER = SOLL_NUMBER), shrinks at the beginning. For any word that is read, an entry of type ELEM() is created with a marker in its VALUE field. If the word that corresponds to the entry which is appended to the list matches PATTERN, the value is 1, otherwise 0. If the value is 1, the number of matching words (PASSEND) in the present cluster is augmented. Once a word is removed from the cluster (after it has reached its size), it is established whether the corresponding VALUE field of the first list item is 1 or zero. If it is 1, one matching word leaves the cluster and the number of matching words is reduced by 1. For any single word, the program performs a percentage calculation of matching words (>PASSEND) in regard to actual cluster size (IST_NUMBER) and writes the results into a growing disc file. The absolute maximum and minimum values as well as a running total of all values are held in global variables. On these, a few analytical calculations are performed after all words have been processed to get the average percentage value, maximum and minimum etc.
The algorithm entails that when reading a given text of size a (in words) at the beginning of the text the cluster of desired size n grows from 0 to n, whereas at the end it shrinks from n to size 0. Without further restrictions, we would get a + n results, which would be wrong. Therefore, we keep track of the cluster’s size and output the results at the beginning of the only, after it has reached size n/2, and at the end until it falls below this number. Thus, for even and uneven numbers of words in the text we make sure that we get exactly one frequency value for any single word.
The graphics program that puts the results on the screen has been implemented for the Hercules(R) graphics card only, because when I began with these studies, my largest machine was equipped with such a device. The program can be fed an optional list of work boundaries. These are marked with dotted lines accross the graph, whereas the regions, where the cluster grows or shrinks at the beginning and at the end, are marked with solid lines. This gives an indication of whether the cluster size has been chosen appropriately to the size of the single works or items of the text.
Doing Statistics with V&F
Such frequency clusters give only a rough idea of which linguistic characteristics might vary or remain constant over a given text. V&F’s own concordance statistics provide only rudimentary functions: Because of the great variety of possible investigative aims, an access system like V&F can hardly cater for different enough statistical needs. Programs to perform t-, F- and Chi-2-analysis have therefore been written on-the-spot in SPITBOL to compare the frequencies of function words in the Historia Augusta with those in Suetonius and to mark the results according to table values of significance thresholds.
One of the immediate results of this research has been that the Historia Augusta is much less homogeneous in style than are the biographies of Suetonius, which by themselves are known to vary in styledness; the biographies of Cornelius Nepos, too, show less variation in function word usage. The variances of small function words in Suetonius are significantly smaller than in the Historia Augusta, and the frequencies vary with single works. Thus, the single-author hypothesis, seemingly proven by earlier attempts at using a computer to analyze the work, has been called into question by the studies described in this paper. The same methods have been used to group biographies by stylistic similarities. The last group in the series as well as the one trading under the name of Julius Capitolinus seem homogeneous in themselves, but differ between each other, making it the more unlikely that the whole set of biographies should have been written from scratch by one and the same person.
Putting it on the Net
Since V&F and its accompanying programs use ordinary DOS I/O calls, they can be run without problems off a Novell Netware(R) file server. Recently, we could get funds from the German Science Foundation (DFG) to build a network at the Halle Classics Department with a huge central file and CD server and workstations on every researcher’s writing table. Besides the aforementioned commercial text bases and a couple of bibliography systems, there are all the beta code texts on the server that are available today, accessible through centrally served V&F. Concurrently to Novell SPX, the net runs TCP/IP to provide internet services to all users(Thanks to Marcus Nenninger, M.A., friend and colleague, for his collaboration (and patience). Besides, others have helped at establishing this research network: The Universitätsrechenzentrum of Martin Luther Universität Halle-Wittenberg, H.Loehr, Prof. Dr. W.Luppe and the former dean of the faculty, Prof. Dr. K.D.Jaeger.) The work stations are configured differently for MS-Windows(R), plain MS-DOS(R) and/or DESQView/X(R), and V&F had to be set up to be stable under these different systems.
As M.Nenninger (1994) writes: Given humanists‘ different research interests and methods, flexibility is a major issue in humanities computing. SPITBOL’s efficiency has been sufficient for the purpose, at least on modern powerful platforms (The ordinary workstation at the Robertinum Halle is powered by an Intel(R) 80486DX-2 with 66MHz. For practical applications in text processing, these machines are fast enough. For graphics applications, we have a few Pentium-machines, too. Besides, there is access to the university’s RISC cluster /RS 6000 under IBM-AIX/ with X-windows capabilities.) The V&F experience has shown that productive humanities computing can be done using very high-level languages like SPITBOL and exploiting their flexibility potential, powerful string handling capabilities and easy memory management, provided the special requirements in non-Latin script processing can be met. In designing V&F, we have been relying on the SPITBOL external function interface to do graphics and to speed up recurrent elementary routines. Therefore, a major challenge in implementing the system was the integration of externally assembled 32-bit machine routines in the SPITBOL system on a grand scale (Marc Emmer, designer of the SPITBOL-386 system, has given invaluable assistance, and I am much indebted to him for his help.) Putting the system to use to statistically analyze a late Roman collection of biographies has shown that even in an era of ready-made „big“ applications and powerful man-machine interfaces (Recent operating systems implement a graphical user interface directly into the user interaction with the system; character-based interaction is launched from the graphics environment and not vice versa as previously. As a matter of fact, we are somehow irritated by the idea (advanced by the software industry) that after more than 2000 years of letter-based scripts the ultimate progress in human communication should be a return to pictographic systems and deictic behaviour.) complex programming tools like the SNOBOL4 language have an important role to play in humanities computing. With the growing availability of machine- readable texts for classicists, the importance of such programming will probably grow, too, since recent trends in multimedia focus more on presentation issues than on computer-assisted analysis.
Works Cited
S.D’Arco Avalle, Il calcolatore e le scienze umane, in: L.Gallino (a cura di), Informatica e scienze umane – Lo stato dell’arte, Milano (1991) 68-85, bes. 84f.
F.Damerau, The Use of Function Word Frequencies as Indicators of Style, Computers and the Humanities IX (1975) 271-280.
M.Emmer, SNOBOL4+, The SNOBOL4 Language for the Personal Computer User, Englewood Cliffs, N.J. (1985).
M.Emmer, MACROSPITBOL, The High-Performance SNOBOL4 Language, Salida, Co. (1989).
B.Frischer & D.Guthrie & E.Tse & F.Tweedie, ‚Sentence‘ Length and Word-type at ‚Sentence‘ Beginning and End: Reliable Authorship Discriminators for Latin Prose? New Studies on the Authorship of the Historia Augusta, forthcoming in: Research in Humanities Computing VI, Oxford (1996).
J.F.Gimpel, Algorithms in SNOBOL4, New York, London, Sydney, Toronto (1976).
R.E.Griswold & J.F.Poage & I.P.Polonsky, The SNOBOL4 Programming Language, Englewood Cliffs, N.J. (1970).
R.E.Griswold & M.T.Griswold, A SNOBOL4 Primer, Englewood Cliffs, N.J. (1973).
S.Hockey, SNOBOL Programming for the Humanities, Oxford (1985).
E.Johnson, Computer Programming for the Humanities in SNOBOL4, Madison SD (6th ed. 1995).
A.J.P.Kenny, The Stylometric Study of Aristotle’s Ethics, in: S.Lusignan & J.S.North (edd.), Computing in the Humanities, Proceedings of the Third International Conference on Computing in the Humanities, Waterloo (1977) 11-22.
A.J.P.Kenny, The Aristotelian Ethics, Oxford (1978).
A.J.P.Kenny, A Stylometric Study of Aristotle’s Metaphysics, Bulletin of the Association for Literary and Linguistic Computing 7 (1979) 12-21.
A.J.P.Kenny, The Computation of Style, Oxford (1982).
U.Kindermann, Rev. of: Burkhard Meissner, View-&-Find(ing)-Programm, Erlangen 1992, Mitteilungsblatt des Mediaevistenverbandes IX 2 (1992) 31-32.
I.Marriott, The Authorship of the Historia Augusta: Two Computer Studies, JRS 69 (1979) 65-77.
B.Meissner, TLG und PHI CD-ROM: Ein neuer Zugang…, Gnomon LXIII (1991) 670- 671.
B.Meissner, Sum enim unus ex curiosis: Computerstudien zum Stil der Scriptores Historiae Augustae, RCCM XXXIV 1 (1992) 47-79.
B.Meissner, Geschichtsbilder in der Historia Augusta, Philologus CXXXVII (1993) 274- 294.
B.Meissner, V&F: sistema interattivo per l’analisi dei testi greci e latini, Bollettino d’Informazioni (Centro di Ricerche Informatiche per i Beni Culturali) III 1, Pisa (1993) 57-68 (http://www.cribecu.sns.it/b31/vf.html).
B.Meissner, Computergestuetzte Untersuchungen zur stilistischen Einheitlichkeit der Historia Augusta, forthcoming in Bonner Historia Augusta Colloquium (BHAC) 1994.
F.Mosteller & D.L.Wallace, Inference and Disputed Authorship: The Federalist, Reading, Mass. (1964).
C.Muller & E.Brunet, La statistique résout-elle les problèmes d’attribution?, Strumenti critici 58 (1988) 367-387.
M.Nenninger, Computergestuetzte Analyse antiker Texte: Projekte des Instituts fuer Klassische Altertumswissenschaften der Martin-Luther-Universitaet Halle-Wittenberg, in: M.Fell & C.Schaefer & L.Wierschowski (edd.), Datenbanken in der Alten Geschichte, St. Katharinen (1994) 187-193.
W.W.Peterson, Introduction to Programming Languages, Englewood Cliffs, N.J. (1974) ch. 9.
A.Russo, SNS Greek & Latin 2.0, Bollettino d’Informazione III 1 [Pisa] (1992) 68-74 (http://www.cribecu.sns.it/b31/snsg&l20.html).
A.Santoni, SNS-Greek 3.1. Uno strumento per l’utilizzazione del CD-ROM versione „C“ del Thesaurus Linguae Graecae, in: P.R.Colace & M.C.Caltabiano (edd.), Atti del I seminario di studi lessici tecnici greci e latini, Accad. pelorit. dei pericolanti, Cl. di lett. e filos. e BB.AA, Suppl. 1, vol 66, Messina (1990) 47-61.
A.Santoni & L.Bondi & A.Russo, Présentation du logiciel SNS-Greek, outil de consultation du TLG, in: Lalies. Actes des sessions de linguistique et de littérature 11, Paris (1992) 225-229.
C.Schaefer, Computer und antike Texte, St.Katharinen (1993) 135-218 & 227-231.
D.Sansone, The Computer and the Historia Augusta: A Note on Marriott, JRS 80 (1990) 174-177.
Letzte Änderung: 21. März 2018